The promise of faster time to market has made microservices very popular over the past few years and unlike its predecessors such as CORBA & SOA, it continues to remain popular despite many of the inherent complexities associated with it. What makes microservices so popular is exactly what also makes it so complex. The system abstraction is divided into smaller units, making management of the individual units more efficient but taking a toll when looked at as a whole. Couple this with the fact that scale demands are ever increasing, and availability demands are becoming stringent, the need to better manage these complexities has become an integral part of microservices based systems. An organization adopting microservices must weigh in the pros and cons of various approaches, fitment in their world and effort required to evolve should the need to change arise. This article provides a high-level overview of these complexities and some of the practices, solutions that are commonly used to resolve it.
Integration between services
This has been an ever-evolving area, from direct communication between peer services, to using an intermediary such as API GW or message bus, to making use of the proxy-based communication hooks offered by some of the newer frameworks.
Direct or API GW based integration is very easy to understand. With API GW, one gets other benefits such as centralized control, single-entry point for all external links etc. The downside of this model is that most of the implementations are HTTP/REST which is a blocking communication. This in turn requires several architectural controls such as circuit breaker, bulkhead and are discussed in the later sections. It also requires an additional Load balancer component for each of the service so as to support availability using multiple instances.
Message bus based integration is a completely different programming paradigm and may look tedious initially, however, the advantages are numerous. It simplifies the deployment setup by removing the need for load balancers and service discovery. It handles all aspects of message delivery, freeing up clients from those complexities. Most importantly, it leads to asynchronous integration and makes the systems more decoupled and resilient to failures. Additionally, message bus can be easily integrated with external systems without doing any changes to the existing applications.
Proxy based communication handles all of the cross-cutting concerns such as authentication and authorization, metrics collection, policy controls so that application logic is freed up from these responsibilities. This is a significant advantage as it frees up application developers to focus on the business logic and also allows reuse of the boiler plate code across all the services. Frameworks such as Istio provide the necessary tools to manage these kinds of deployments. Istio is based on Kubernetes and uses custom resources to implement the policy controls and framework tooling.
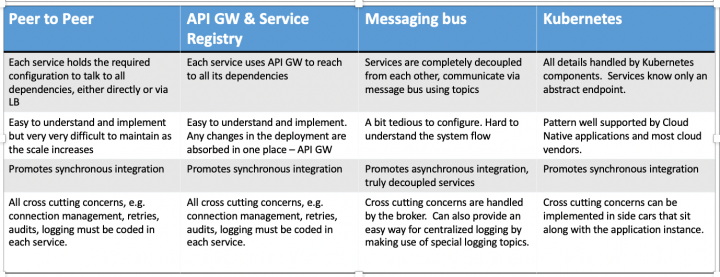
Figure 1: Comparison of various integration methods
Preventing cascading failures, making the system more resilient
As the scale of the microservices grows, the number of instances in the overall system grow and so do the dependencies between the services. In a very large scale distributed systems, it’s almost always true that some or the other instances are not in good health – may be there’s a software upgrade or the upgrade itself is bad, may be there’s memory or load pressure and the instance is very slow to respond, may be the underlying computing infrastructure crashed or maybe there’s a network issue.
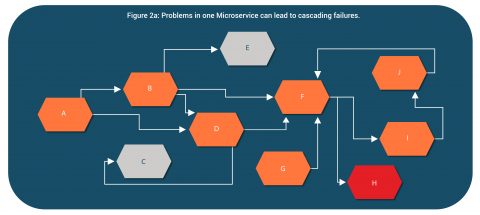
For example, consider Figure 2 and 2a below illustrating a microservices based system and dependencies within. An issue in Service H, initially started causing issues in services F, D.
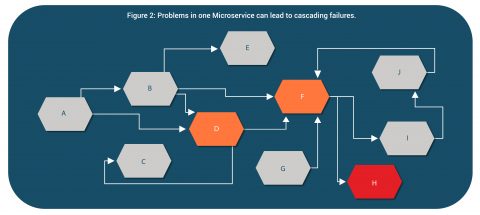
With time and more incoming requests, it started impacting all the services which were directly or indirectly linked with it. This eventually leads to outage in the entire system.
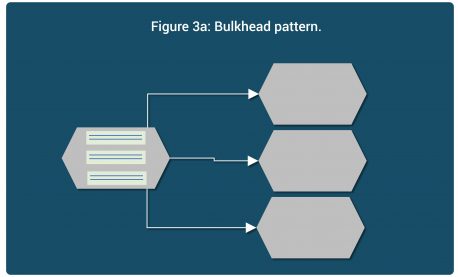
There are patterns like bulkhead and circuit breaker which can be used to protect against these issues.
In bulkhead, a calling microservice partitions its resources for every dependency so any issues in a dependency affects only those resources and the microservice by and large can continue to function and prevent the failure from cascading further down.
For example, in Figure 3a, a microservice uses separate thread pools (or perhaps applies max limits) for each of the dependency.
In circuit breaker, a calling microservice keeps a tab on all outgoing connections and if it observes any issues with the connection then temporarily shuts off outgoing calls on that path, saving its own resources. Example of the same is illustrated in Figure 3b.
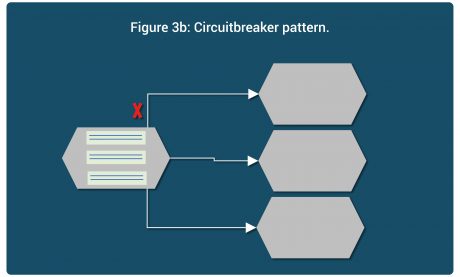
In summary, care must be taken at every microservice level to protect itself from failures in the dependencies and prevent the failure from cascading to other services.
Data handling
Data handling can get very tricky when there are multiple microservices involved. A high-level business transaction will now get operated upon by several services. Imagine handling a 2-phase commit when it’s spread across multiple services and when service instances can arbitrarily go down or have network latencies or reachability issues. That’s a nightmare from programming and operations perspective.
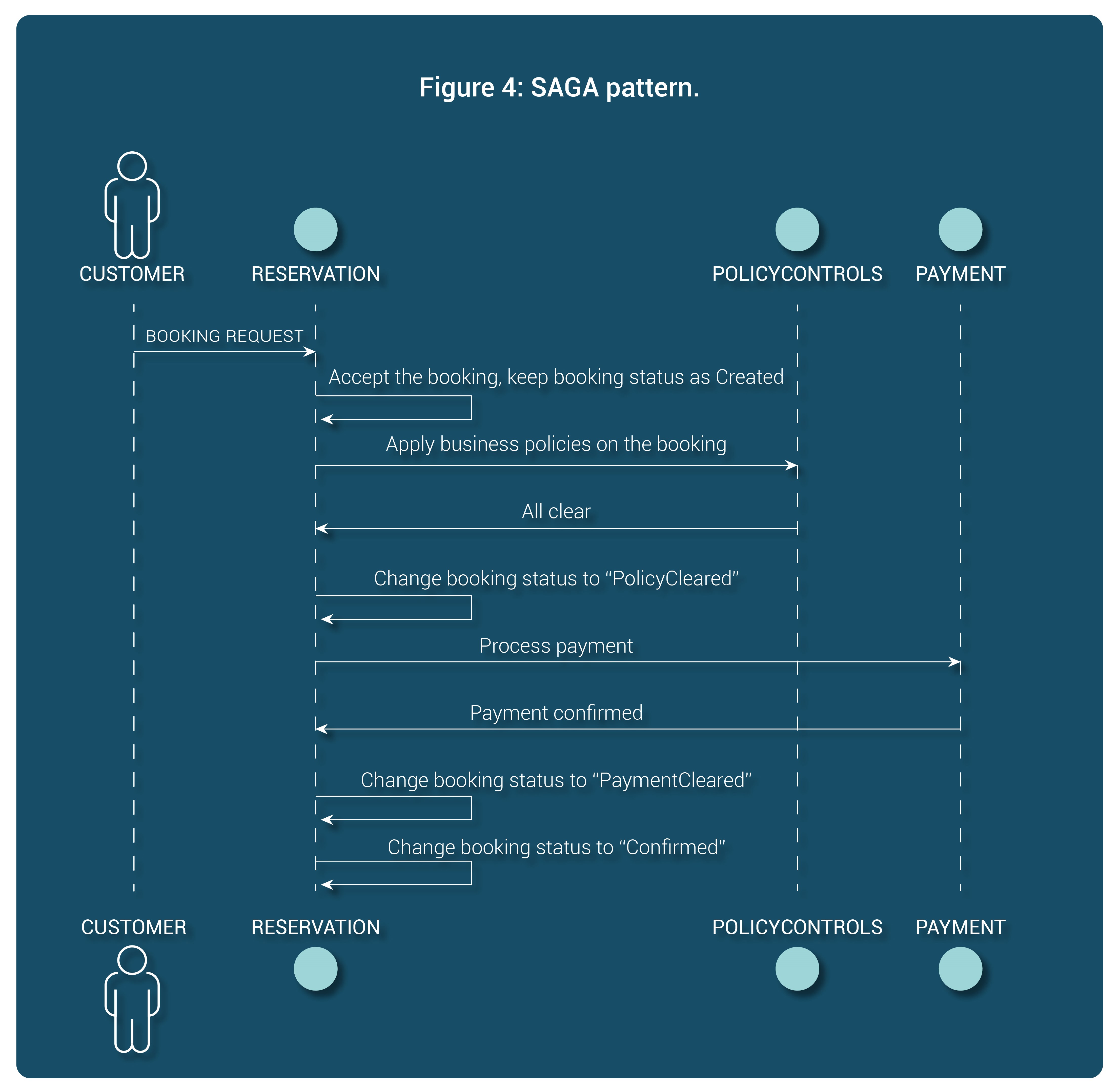
This necessitates that ACID guarantees now must be handled only at a unit/service level and cannot span the entire business operation. This is typically handled by the SAGA pattern. In this pattern, a coordinating microservice uses fine grained states to accommodate separate transactions for each of the dependency. This allows to keep transactions at the individual services atomic &
rollbackable.
Figure 4 below illustrates this. A reservation system uses multiple states for the booking request to keep track of what backend operation is being performed for that booking. Only when all of the backend operations are complete, it marks the booking status to “Confirmed”. If there are failures in between, it can either retry or rollback the transactions at each of the backend services.
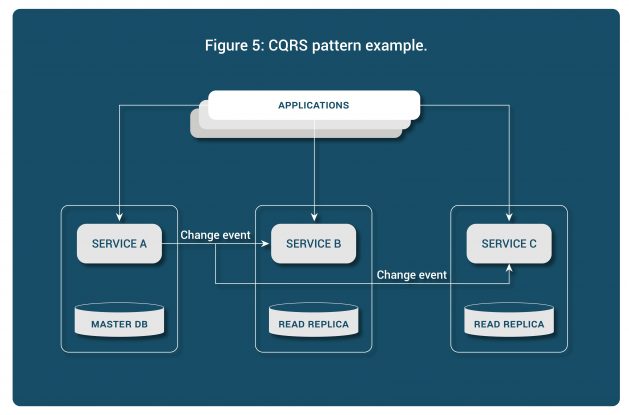
Sometimes the need is to share data between microservices. A unit of data is owned by a single service, but other services may need read access to it. For these situations a CQRS, command and query responsibility segregation pattern is used wherein the producer and the consumer paths for the data in question are kept separate. In the figure below, data owned by Service A is never directly accessed by Service B and C. Instead they keep their own copies of the data, perhaps in a different format, and subscribe to any changes to that data. Note that the read copies with Service B and C may at times be stale but will eventually become consistent with the master data copy.
Deployment
This is an area that’s often ignored by the developers but is of utmost importance. Installing and maintaining applications in production is a mammoth task and an array of technologies are available to make this simpler. The advent of Cloud vendors has taken many of the basic infrastructure level tasks out of the way and cloud native deployment frameworks like Kubernetes are making it easier from management perspective.
One must strive to use declarative configuration for the deployment so the expected configuration state can be version controlled, changes can be reviewed and then applied. Be very careful about automation as there’s nothing called “safe-automation”. Anything that changes the state of the production systems can potentially be harmful in some or the other way. For example, scaling up resources is considered safe but the side effects of the same are going to show up in your next bill.
It’s important to practice canary deployments which allow production rollouts to be applied to a subset of customers to ensure- not everyone is impacted should anything go wrong. Upgrades usually mean bringing down the old instances and spawning new, this is made easier with blue-green deployment methodologies.
Other important considerations
There are a few other aspects that needs attention too.
The freedom to pick technology best suited for the service can lead to technology explosion. Maintaining hundreds or thousands of 3
rd party libraries in production is not practical and is downright risky from a security point of view.
Service boundaries must be chosen carefully. This has implication on the number of services that need to be managed, inter dependencies, complexity of the integration test environment, monitoring and so forth.
Summary
In summary, most companies are embracing this architecture style to bring in efficiencies in the development and rollout of their software systems. In doing so, care must be taken to evaluate areas that are known to bring in complexities, consider various patterns, solutions that can be applied to these areas, so the move to Microservices can be better managed.
